Data
The datasets for week 1 are very interesting: Tweets with the #rstats and #TidyTuesday hashtags.
These datasets were obtained using the rtweet package, which is a very practical package for getting Twitter data. I’ve used a couple of other packages in the past (some years ago), but this one is very easy to use and contains many utility functions that can make your life easier.
For example, to get some tweets with the #TidyTuesday hashtag you can run this (previous configuration is needed):
rt <- search_tweets("#TidyTuesday", include_rts = FALSE)
For the purpose of this post, the dataset I’ve chosen to analyze is the one with the #TidyTuesday hashtag tweets. Let’s take a quick look at it:
library(tidyverse)
tidytuesday_tweets <- read_rds(url("https://github.com/rfordatascience/tidytuesday/blob/master/data/2019/2019-01-01/tidytuesday_tweets.rds?raw=true"))
tidytuesday_tweets %>%
skimr::skim()
## Skim summary statistics
## n obs: 1565
## n variables: 88
##
## -- Variable type:character ----------------------------------------------------------------------------------------------------
## variable missing complete n min max empty n_unique
## account_lang 0 1565 1565 2 5 0 12
## country 1536 29 1565 6 14 0 5
## country_code 1536 29 1565 2 2 0 5
## description 0 1565 1565 0 160 91 431
## ext_media_type 1565 0 1565 Inf -Inf 0 0
## lang 0 1565 1565 2 3 0 5
## location 0 1565 1565 0 41 210 298
## name 0 1565 1565 2 49 0 478
## place_full_name 1536 29 1565 10 22 0 21
## place_name 1536 29 1565 6 14 0 21
## place_type 1536 29 1565 4 5 0 2
## place_url 1536 29 1565 56 56 0 21
## profile_background_url 184 1381 1565 48 49 0 17
## profile_banner_url 232 1333 1565 55 68 0 379
## profile_expanded_url 593 972 1565 15 100 0 307
## profile_image_url 0 1565 1565 60 110 0 473
## profile_url 593 972 1565 22 23 0 308
## quoted_description 1362 203 1565 0 160 6 80
## quoted_location 1362 203 1565 0 30 14 68
## quoted_name 1362 203 1565 3 30 0 84
## quoted_screen_name 1362 203 1565 3 15 0 84
## quoted_source 1362 203 1565 6 19 0 10
## quoted_status_id 1362 203 1565 18 19 0 159
## quoted_text 1362 203 1565 37 328 0 159
## quoted_user_id 1362 203 1565 7 19 0 84
## reply_to_screen_name 1323 242 1565 3 15 0 149
## reply_to_status_id 1351 214 1565 18 19 0 209
## reply_to_user_id 1323 242 1565 6 19 0 149
## retweet_description 1565 0 1565 Inf -Inf 0 0
## retweet_location 1565 0 1565 Inf -Inf 0 0
## retweet_name 1565 0 1565 Inf -Inf 0 0
## retweet_screen_name 1565 0 1565 Inf -Inf 0 0
## retweet_source 1565 0 1565 Inf -Inf 0 0
## retweet_status_id 1565 0 1565 Inf -Inf 0 0
## retweet_text 1565 0 1565 Inf -Inf 0 0
## retweet_user_id 1565 0 1565 Inf -Inf 0 0
## screen_name 0 1565 1565 3 15 0 478
## source 0 1565 1565 5 23 0 27
## status_id 0 1565 1565 18 19 0 1565
## status_url 0 1565 1565 49 62 0 1565
## text 0 1565 1565 12 460 0 1564
## url 593 972 1565 22 23 0 308
## user_id 0 1565 1565 6 19 0 478
##
## -- Variable type:integer ------------------------------------------------------------------------------------------------------
## variable missing complete n mean sd p0
## favorite_count 0 1565 1565 14.59 27.61 0
## favourites_count 0 1565 1565 4092.71 7996.18 0
## followers_count 0 1565 1565 1379.95 4220.64 0
## friends_count 0 1565 1565 673.24 1640.44 0
## listed_count 0 1565 1565 43.3 135.06 0
## quoted_favorite_count 1362 203 1565 380.19 3430.77 0
## quoted_followers_count 1362 203 1565 18561.22 108157.09 11
## quoted_friends_count 1362 203 1565 1125.85 6150.53 0
## quoted_retweet_count 1362 203 1565 144.59 1340.41 0
## quoted_statuses_count 1362 203 1565 5204.85 9770.54 11
## retweet_count 0 1565 1565 2.99 6.21 0
## retweet_favorite_count 1565 0 1565 NaN NA NA
## retweet_followers_count 1565 0 1565 NaN NA NA
## retweet_friends_count 1565 0 1565 NaN NA NA
## retweet_retweet_count 1565 0 1565 NaN NA NA
## retweet_statuses_count 1565 0 1565 NaN NA NA
## statuses_count 0 1565 1565 4038.11 16662.49 1
## p25 p50 p75 p100 hist
## 3 9 17 494 ▇▁▁▁▁▁▁▁
## 365 1381 5794 97420 ▇▁▁▁▁▁▁▁
## 72 290 1450 76469 ▇▁▁▁▁▁▁▁
## 182 504 669 42568 ▇▁▁▁▁▁▁▁
## 2 9 54 2452 ▇▁▁▁▁▁▁▁
## 13 25 49 44919 ▇▁▁▁▁▁▁▁
## 480 1927 1927 1074706 ▇▁▁▁▁▁▁▁
## 492 669 669 87765 ▇▁▁▁▁▁▁▁
## 2 7 16 17154 ▇▁▁▁▁▁▁▁
## 1030.5 3209 3209 68220 ▇▁▁▁▁▁▁▁
## 0 2 3 95 ▇▁▁▁▁▁▁▁
## NA NA NA NA
## NA NA NA NA
## NA NA NA NA
## NA NA NA NA
## NA NA NA NA
## 146 1063 3209 387401 ▇▁▁▁▁▁▁▁
##
## -- Variable type:list ---------------------------------------------------------------------------------------------------------
## variable missing complete n n_unique min_length
## bbox_coords 0 1565 1565 22 8
## coords_coords 0 1565 1565 2 2
## ext_media_expanded_url 564 1001 1565 1001 1
## ext_media_t.co 564 1001 1565 1001 1
## ext_media_url 564 1001 1565 1001 1
## geo_coords 0 1565 1565 2 2
## hashtags 37 1528 1565 537 1
## media_expanded_url 564 1001 1565 1001 1
## media_t.co 564 1001 1565 1001 1
## media_type 564 1001 1565 2 1
## media_url 564 1001 1565 1001 1
## mentions_screen_name 959 606 1565 324 1
## mentions_user_id 959 606 1565 324 1
## symbols 1565 0 1565 0 NA
## urls_expanded_url 735 830 1565 726 1
## urls_t.co 735 830 1565 789 1
## urls_url 735 830 1565 490 1
## median_length max_length
## 8 8
## 2 2
## 1 4
## 1 4
## 1 4
## 2 2
## 2 19
## 1 2
## 1 2
## 1 2
## 1 2
## 1 25
## 1 25
## NA NA
## 1 5
## 1 5
## 1 5
##
## -- Variable type:logical ------------------------------------------------------------------------------------------------------
## variable missing complete n mean
## is_quote 0 1565 1565 0.13
## is_retweet 0 1565 1565 0
## protected 0 1565 1565 0
## quoted_verified 1362 203 1565 0.03
## retweet_verified 1565 0 1565 NaN
## verified 0 1565 1565 0.0019
## count
## FAL: 1362, TRU: 203, NA: 0
## FAL: 1565, NA: 0
## FAL: 1565, NA: 0
## NA: 1362, FAL: 197, TRU: 6
## 1565
## FAL: 1562, TRU: 3, NA: 0
##
## -- Variable type:numeric ------------------------------------------------------------------------------------------------------
## variable missing complete n mean sd p0 p25 p50 p75 p100
## display_text_width 0 1565 1565 174.32 75.95 12 112 180 246 294
## hist
## ▂▃▆▆▅▆▇▇
##
## -- Variable type:POSIXct ------------------------------------------------------------------------------------------------------
## variable missing complete n min max median
## account_created_at 0 1565 1565 2007-02-01 2018-12-06 2013-03-04
## created_at 0 1565 1565 2018-04-02 2018-12-19 2018-07-18
## quoted_created_at 1362 203 1565 2018-01-17 2018-12-17 2018-07-09
## retweet_created_at 1565 0 1565 NA NA NA
## n_unique
## 478
## 1560
## 159
## 0
For the purpose of this post, I will just select some columns:
tidytuesday_tweets <- tidytuesday_tweets %>%
select(screen_name, status_id, created_at, text, retweet_count, favorite_count)
tidytuesday_tweets
## # A tibble: 1,565 x 6
## screen_name status_id created_at
## <chr> <chr> <dttm>
## 1 Eeysirhc 1075264883367632896 2018-12-19 05:41:40
## 2 Eeysirhc 1072728604440580096 2018-12-12 05:43:24
## 3 Eeysirhc 1074488199907500032 2018-12-17 02:15:24
## 4 clairemcwhite 1075197256062644224 2018-12-19 01:12:56
## 5 stevie_t13 1075186982203084801 2018-12-19 00:32:07
## 6 stevie_t13 1072518335001169920 2018-12-11 15:47:52
## 7 thomas_mock 1074664472634109952 2018-12-17 13:55:51
## 8 thomas_mock 1075028993345245185 2018-12-18 14:04:19
## 9 thomas_mock 1072163012327415808 2018-12-10 16:15:56
## 10 thomas_mock 1075173440481579010 2018-12-18 23:38:18
## text
## <chr>
## 1 "#tidytuesday getting back into the keywords game this week with a lit~
## 2 "#tidytuesday despite what they say NY hotdog stands have some of the ~
## 3 "I realize it's a Sunday night but I wasn't too happy with my last #ti~
## 4 "@thomas_mock Maybe a shorter one line subtitle, like \"Weekly data pr~
## 5 #BeckyG #TidyTuesday https://t.co/2gMf6QLVz1
## 6 #ArianaGrande #thankunext #TidyTuesday https://t.co/2g3ZrEbZIL
## 7 "The @R4DScommunity welcomes you to week 38 of #TidyTuesday! We're ex~
## 8 "#r4ds community, please vote on a #TidyTuesday hex-sticker! \n\n<U+26A0><U+FE0F><U+26A0><U+FE0F> ~
## 9 "The @R4DScommunity welcomes you to week 37 of #TidyTuesday! We're ex~
## 10 "@jschwabish @jsonbaik @awunderground Hey @jschwabish this is an aweso~
## retweet_count favorite_count
## <int> <int>
## 1 0 0
## 2 1 7
## 3 1 5
## 4 0 2
## 5 0 0
## 6 0 0
## 7 7 14
## 8 7 11
## 9 7 23
## 10 1 6
## # ... with 1,555 more rows
Wordclouds
In this post, we’ll be exploring the words inside the tweets using wordclouds. This way, we can get a general idea of what the main topics were during the 2018 tidytuesdays.
library(tidytext)
## Warning: package 'tidytext' was built under R version 3.5.2
tidytuesday_words <- tidytuesday_tweets %>%
unnest_tokens(word, text, token = "tweets")
tidytuesday_words
## # A tibble: 42,485 x 6
## screen_name status_id created_at retweet_count favorite_count
## <chr> <chr> <dttm> <int> <int>
## 1 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 2 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 3 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 4 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 5 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 6 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 7 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 8 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 9 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 10 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## # ... with 42,475 more rows, and 1 more variable: word <chr>
Let’s quickly check the word frequency:
tidytuesday_words %>%
count(word, sort = TRUE)
## # A tibble: 7,966 x 2
## word n
## <chr> <int>
## 1 #tidytuesday 1520
## 2 the 1377
## 3 to 1151
## 4 a 834
## 5 and 792
## 6 of 734
## 7 for 691
## 8 #rstats 634
## 9 i 627
## 10 in 579
## # ... with 7,956 more rows
After taking a look at the words, we need to remove some words that we know will affect the analysis. First, we have to remove the stopwords. Then we have to remove some words like “thomasmock” & “R4DScommunity”, which are the user names of the people managing the tidytuesdays, so they will appear a lot in this analysis. Obviously, we have to remove the word “#tidytuesday” (all the tweets contain this hashtag…that’s the reason we are doing this analysis):
tidytuesday_words <- tidytuesday_words %>%
anti_join(stop_words, by = "word") %>%
filter(!(word %in% c("@thomasmock", "@r4dscommunity", "#tidytuesday", "tidytuesday", "#rstats", "#r4ds",
"data", "week", "code", "#tidyverse", "#dataviz", "time", "weeks",
"submission", "plot", "plots", "dataset"))) %>%
filter(!grepl("^http", word), grepl("[a-zA-Z]", word))
tidytuesday_words
## # A tibble: 14,652 x 6
## screen_name status_id created_at retweet_count favorite_count
## <chr> <chr> <dttm> <int> <int>
## 1 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 2 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 3 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 4 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 5 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 6 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 7 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 8 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 9 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## 10 Eeysirhc 107526488~ 2018-12-19 05:41:40 0 0
## # ... with 14,642 more rows, and 1 more variable: word <chr>
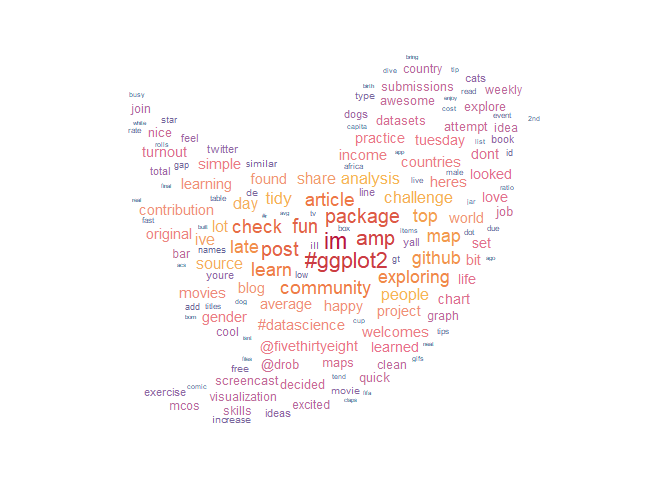
Now, let’s try our first wordcloud with all the words we have:
library(ggwordcloud)
library(ggthemes)
tidytuesday_words %>%
count(word, sort = TRUE) %>%
filter(n > 5) %>%
ggplot(aes(label = word, size = n, colour = n)) +
geom_text_wordcloud() +
scale_size_area() +
theme_minimal() +
scale_colour_gradient2_tableau("Sunset-Sunrise Diverging")

Let’s give some shape to the wordcloud:
library(ggwordcloud)
library(ggthemes)
tidytuesday_words %>%
count(word, sort = TRUE) %>%
filter(n > 5) %>%
ggplot(aes(label = word, size = n, colour = n)) +
geom_text_wordcloud(rm_outside = TRUE,
mask = png::readPNG("twitter_logo_black-nobackground.png")) +
scale_size_area() +
theme_minimal() +
scale_colour_gradient2_tableau("Sunset-Sunrise Diverging")
That’s much nicer! Many words were removed in order to have a neat Twitter-logo-shaped wordcloud. I think some of these removed words are relevant to get a sense of the topics covered in 2018, so I decided to keep both wordclouds, the big one and this twitter-logo-shaped wordcloud (initially, I just wanted the Twitter-logo-shaped one).
And finally, to get a sense of the weekly topics, lets try a wordcloud by week:
library(lubridate)
tidytuesday_words %>%
mutate(week = as.Date(floor_date(created_at, "week", week_start = 1))) %>%
count(week, word, sort = TRUE) %>%
group_by(week) %>%
filter(row_number(desc(n)) <= 40) %>%
mutate(sz = n / max(n)) %>%
ungroup() %>%
ggplot(aes(label = word, size = sz, colour = sz)) +
geom_text_wordcloud(rm_outside = TRUE) +
scale_radius(range = c(1, 5)) + #scale_size_area(max_size = 5) +
theme_minimal() +
scale_colour_gradient2_tableau("Sunset-Sunrise Diverging") +
facet_wrap(~week, ncol = 4, scales = "free")

Nice! Now we can easily spot the main topics covered during 2018 TidyTuesdays.
Conclusion
As you can see, you can get a good overview of the topics in a text by using just wordclouds. Some data cleaning is necessary, but the results are worthwhile.
All the code in here can be found in my github repo: TidyTuesdayCode